Overview
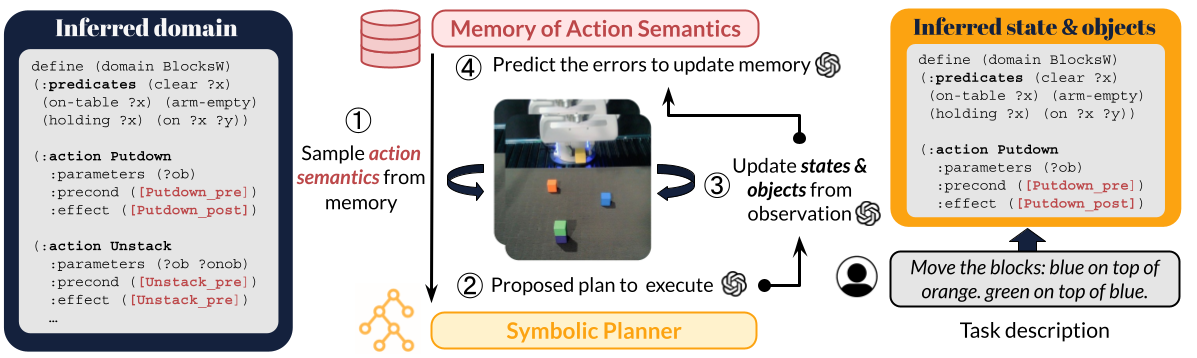
We propose PSALM-V, the first autonomous neuro-symbolic learning system able to induce symbolic action semantics (i.e., pre- and post-conditions) in visual environments through interaction. PSALM-V bootstraps reliable symbolic planning without expert action definitions, using LLMs to generate heuristic plans and candidate symbolic semantics. Previous work has explored using large language models to generate action semantics for Planning Domain Definition Language (PDDL)-based symbolic planners. However, these approaches have primarily focused on text-based domains or relied on unrealistic assumptions, such as access to a predefined problem file, full observability, or explicit error messages. By contrast, PSALM-V dynamically infers PDDL problem files and domain action semantics by analyzing execution outcomes and synthesizing possible error explanations. The system iteratively generates and executes plans while maintaining a tree-structured belief over possible action semantics for each action, iteratively refining these beliefs until a goal state is reached. Simulated experiments of task completion in ALFRED demonstrate that PSALM-V increases the plan success rate from 37% (Claude-3.7) to 74% in partially observed setups. Results on two 2D game environments, RTFM and Overcooked-AI, show that PSALM-V improves step efficiency and succeeds in domain induction in multi-agent settings. PSALM-V correctly induces PDDL pre- and post-conditions for real-world robot BlocksWorld tasks, despite low-level manipulation failures from the robot.
PSALM-V takes as input a natural language task description and a list of domain action signatures (a string name for the action and the type and number of arguments it takes) and predicts both the problem file and the action semantics, i.e., the preconditions and postconditions of actions in the domain file. The full pipeline of PSALM-V comprises six main steps.
For Step 1 and Step 3, we perform prospection for \( k = 5 \) steps on LLM output to ensure the first few actions are valid under the inferred domain and problem file.
PSALM-V remains robust even in the presence of low-level execution failures, such as mis-manipulating the target object, as in the video above, where the robot mistakenly stacks the blue cube on the orange cube.
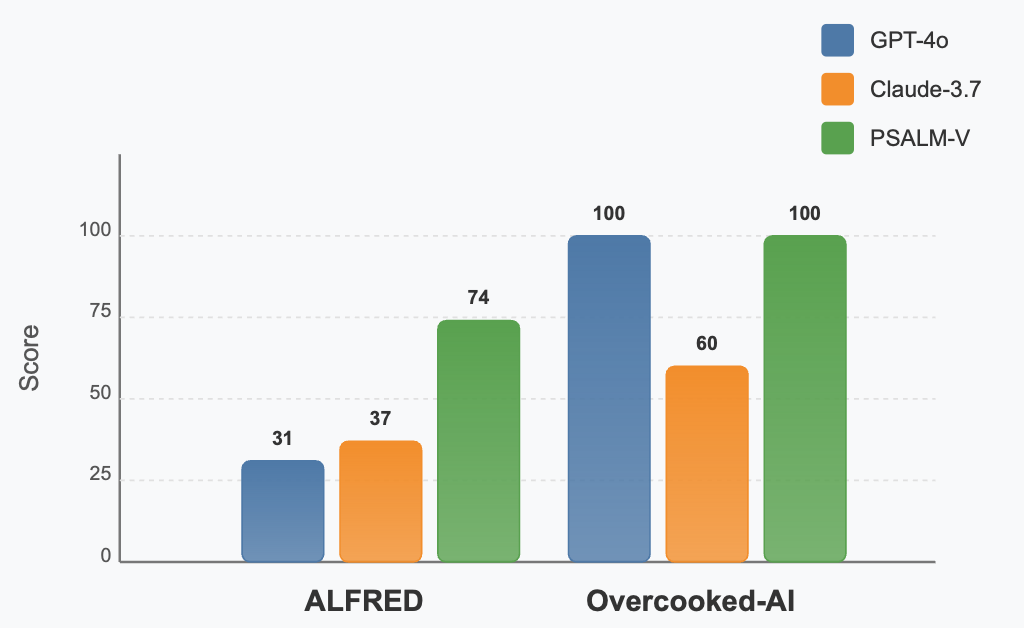
PSALM-V enables strong planning after domain induction. LLMs alone struggle with partially observed planning tasks. Compared to Claude-3.7 and GPT-4o, PSALM-V more than doubles the SR on ALFRED and achieves consistently robust performance, maintaining a 100% win rate, on both RTFM and OverCooked-AI.
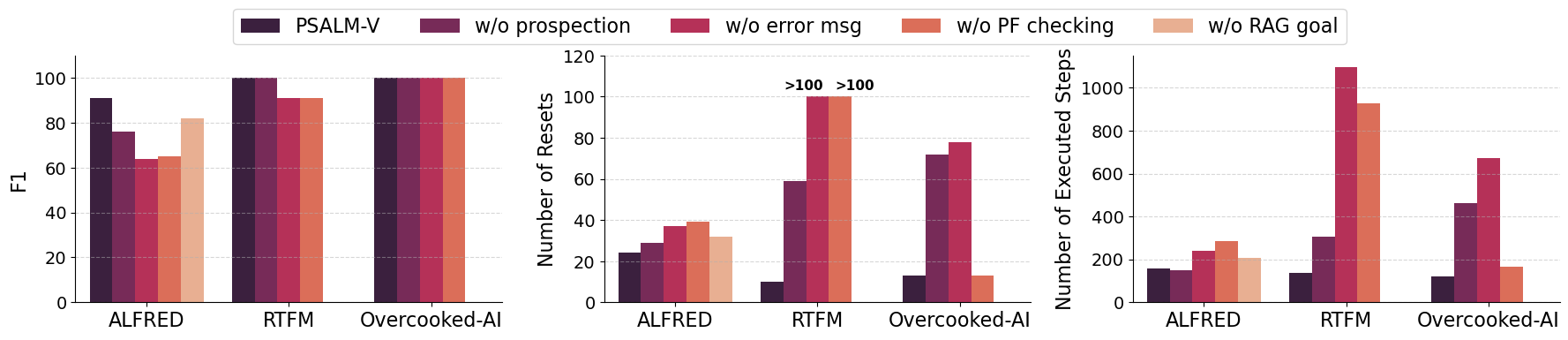
All components of PSALM-V contribute to accuracy and step efficiency. Removing components of PSALM-V leads to reduced F1 scores and increased execution cost, as measured by Number of Resets (NR) and Number of Executed Steps (NES). For example, disabling problem file checking causes NES to spike from 158 to 287 (nearly 2x) in ALFRED and from 135 to 928 (nearly 7x) in RTFM, reflecting inefficient exploration due to undetected problem file errors.